Metrics Treemaps
Are there too many classes in my codebase that are excessively large and complex? Are there some classes that stand out for closer inspection?
As the old expression goes, finding a needle in a haystack is a troubling proposition. Similarly, sifting through hundreds of thousands of lines of code to find those classes or modules which are the potential pain points for you and your team is equally troubling.
Given a large codebase with numerous classes it is difficult to make statements about the overall quality by just exploring the codebase with an IDE. Sure, the IDE allows us to navigate easily to any of the classes but we don’t know which class to look at, and when opening a class we can only see a screenful of code at time. Finding a piece of particularly good or worrysome code ends up being a matter of luck, or intuition. How can we easily and repeatably find the needles in the haystack?
A metrics treemap visualizes the codebase by combining the package or namespace structure with code metrics such as class size and complexity. This highlights areas of concern while showing the distribution of key metrics across the codebase.
What you’ll see
If you’ve never seen or played with treemaps before a good way to get your feet wet is to try one of two tools. For Windows download and run SpaceSniffer (http://www.uderzo.it/main_products/space_sniffer/index.html). For Mac download Disk Inventory X (http://www.derlien.com/). Both will produce nice treemaps of your hard disk to show you what’s eating up the most disk space.
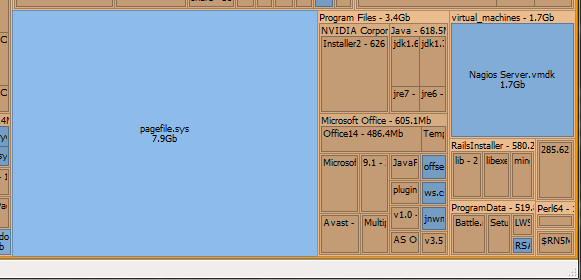
As you can see the treemap organizes your directories as thin rectangles that hold the files. The files are the larger rectangles which grow in size based on the size of the files. For example, you can see that that the file pagefile.sys, the Windows file used for virtual memory swaping, is a massive 7.9GB of space. You’ll also notice that the color of the file rectangles are different and in this case visualize if the file has been accessed recently. The pagefile.sys on this system hasn’t been accessed for over 14 hours and so is shaded blue.
This becomes a powerful tool to see not only where the big files on your hard drive are, but also which ones haven’t been accessed lately and are potential candidates for removal. Just don’t go deleteing your pagefile.sys - it’s kinda important! Now think of the power of using a treemap when applied to code metrics, you’ll be able to quickly zero in on problems across the entire codebase.
Treemaps visualise two class-based metrics for the entire codebase. The class is the most important item in this view and for this reason rectangles representing the classes take up most of the space. The rectangles are sized and coloured based on the values of the two metrics. For example, the size of the rectangle corresponds to the size of the class, measured in lines of code. The colour is a shade of red corresponding to the complexity of the code in the class, the more complex the code, the redder the rectangle.
Classes belong to a package or namespace. We will use the term package from here on but everything applies equally to namespaces in languages that have them. In a metrics treemap the classes in a package are grouped together and placed into a rectangle representing that package. This surrounding rectangle fits snugly around the class rectangles, providing only extra space for a label holding the name of the package. By convention the little extra space the package rectangle needs uses a neutral colour, usually grey or white.
Packages are nested and so are the rectangles representing packages in a metrics treemap. Each package rectangle groups the contained packages and class rectangles. The actual layout of the rectangles inside their enclosing rectangle is governed by a tiling alogorithm, which we’ll discuss in detail later.
Example: The JRuby Code Base
JRuby is a java implementation of the ruby programming language. It allows developers to run ruby code on the Java Virtual Machine (JVM). The project has been running since 2006, and so provides us a mature code base to examine. Building a treemap can help get an idea of the overall quality of JRuby’s code and find areas of particular complexity.
Lines of code and complexity in the JRuby codebase
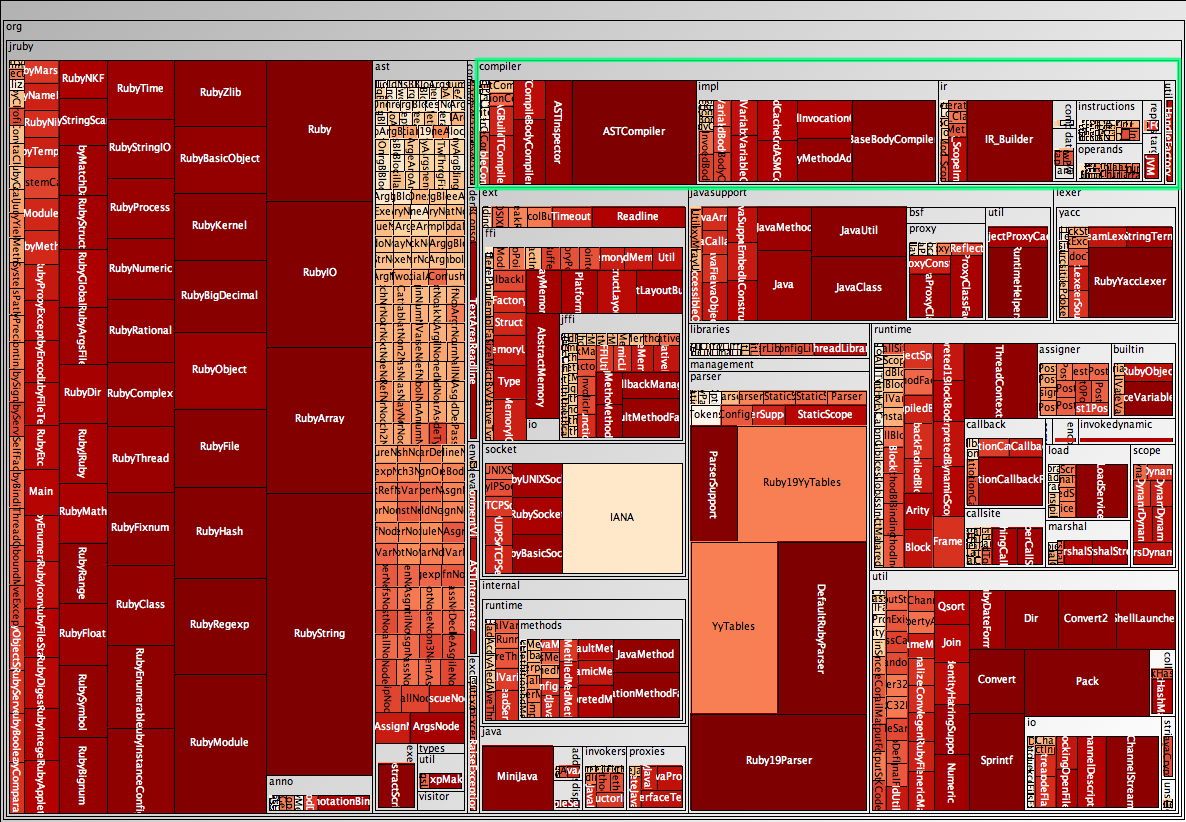
At the top right of the JRuby treemap the org.jruby.compiler package is highlighted. The tree map shows that this package contains a few classes, such as ASTCompiler and ASTInspector, as well as three subpackages, namely impl, ir, and util, with util containing a class called HandleFactory, visible on the far right.
In this example the size of the rectangle represents the number of lines in the corresponding file while the colour shows the sum of the cyclomatic complexity of all the methods in the class; the darker red the class, the higher the complexity.
{jm: ref to cyclomatic complexity - refer to glossary or earlier chapter?}
This map easily identifies large and complex classes. Also, it suggests that file size and complexity are correlated, as the larger rectangles appear in a darker shade of red. The left third of the JRuby tree map follows this pattern almost perfectly. However, the tree map also highlights an exception to this pattern: the IANA class in the org.jruby.ext.socket package. This class is large but has a very low complexity, not only for a class of its size but in general. When looking at the source code, it becomes clear that this is caused by a large number of constants defined in this class.
We have chosen the number of lines in the file, rather than the sum of the lines of code in all methods even though the latter is the more common definition of lines of code. The reason is that in most codebases the lines of code in a method is very strongly correlated with the cyclomatic complexity. By using the length of the file, variation caused by comments, static definitions, or even commented out code can be taken into account as well. If the distribution of comments are important, maybe because the code in question is a developer framework with a published API, it can make sense to generate a treemap that shows the file size as the size of the rectangles, and the sum of the lines of code of all methods as the shading. This makes it possible to spot the relation between “active” code and comments with relative ease.
How it works
Treemaps are a visualisation technique that works for all tree-like structures where the focus is primarily on the leaves, not the structure created by the branches. In mainstream Object Oriented (OO) languages developers have one way to formally group classes, and that is by assigning the classes to packages, which in turn can be nested in other packages. Because of the nesting the overall structure of the classes and package hierarchy can be seen as a tree, where the packages are the branches and the classes are the leaves. Because of the importance of classes in OO programming treemaps are a good fit for a visualisation of this structure.
A treemap shows branches and leaves using rectangles. It does this by tiling the rectangles for child branches and leaves inside the rectangle representing their parent. The size of the rectangles are determined by the leaves, where as the rectangles representing the branches are sized just large enough to fit all the children plus a little extra room for a label for the branch. To make the leaf rectangles fill the branch rectangle completely without any empty space a tiling algorithm determines the width and height as a well as the placing of the leaf rectangles.
The leaf rectangles, which represent the classes, have two attributes that can be varied: size and colour. This lets us display two class level metrics by applying them to size and color. It would be possible to show only one metric by leaving the size of the class rectangles uniform or by drawing all leaf rectangles in the same colour. This can be useful in certain circumstances. {jm: what circumstances?}
It is not possible is to to map metrics individually to the width and height of the rectangle. The reason for this limitation is that the placing and proportion of the rectangle needs to be varied by the tiling algorithm.
The Tiling Algorithm
Tiling rectangles of different sizes to create a larger rectangle without any empty space is not a trivial problem. However, several algorithms have been developed to solve this problem for us. Each of the algorithms imposes certain limitations and trade-offs to achieve the goal.
One possible limitation is control over the aspect ratio, that is the ratio of the height to the width of the rectangle. This can be pretty significant limitation, as when we interpret a treemap it is easier to visually interpret it if the rectangles look more like squares. Long and thin rectangles are harder for us to process visually. So, while we might prefer an aspect ratio close to 1, the tiling algorithm might need to vary the aspect ratio in order to produce a tiling without empty spaces.
The most useful tiling algorithm for visualising class metrics is Squarified, which achieves aspect ratios close to 1 at the expense of not preserving an existing ordering of the rectangles in their parent. Because there is no real ordering of classes inside a package this is not a problem. Actually, the IDEs usually display classes alphabetically but this is more out of necessity to have a stable display than out of logic. For this reason giving up ordering is not a problem, and in turn the Squarified tiling algorithm delivers some of the most harmonious looking treemaps.
Metrics Distribution
Mapping a class level metric, lines of code for example, to the size of the rectangle representing the class shows the distribution of a single metric across the codebase. Looking at the treemap you’ll quickly see whether there are parts of the codebase where the metric is exceptionally large or small, or whether the classes all have relatively similar values for the metric.
Classes in the same package are grouped in the rectangle representing their package, and classes in related packages are displayed in neighboring rectangles. This makes it easy for you to see whether the metric has similar values for classes that the developers chose to place in the same or related packages. If an area of the treemap comprises mostly small rectangles then the classes in that part of the package structure are all of a similar size. On the other hand, if small rectangles are intermixed with different sized rectangles and distributed across the map then class size has no relationship with the package structure.
The second metric is mapped to the shading or colouring of the class, allowing you to see the distribution of the two metrics at the same time while also showing a possible correlation between them. If classes of a similar size generally have a similar colour then the two metrics are correlated.
Colour as much as size is well-suited to spot outliers in the individual metric, that is classes with an unsual shade or colour immediately attract your attention. The mapping of two metrics to the two attributes of the rectanlge makes it possbible to spot exceptions in othwerise generally correlated metrics. For example, if small classes are normally light red and large classes dark red then the user can infer that there is a general correlation between the metrics. However, if there is an individual class that is both small and darker in color the class in question presents an exception that is likely a worthwhile investigation.
Variations
Different class-level metrics
It is intuitive to represent a size-based metric of the class as the size of the corresponding rectangle, but it can be worthwhile to map other metrics to the size of the rectangle. For example, a tree map showing complexity via the size and fan-out as colour makes it obvious which complex classes have high fan-out and which ones have not.
{jm: explain fan-out}
This can be useful to identify which overly complex classes can be refactored more easily. In a class that has lower fan-out the complexity is more self-contained, likely allowing for one or more easy Extract Class refactorings. Such a treemap is shown below.
{jm: missing treemap}
Within a set of visualisations it makes sense to reserve a colour for a certain type of treemap. For example, one could use shades of red for treemaps that show size and complexity while using blue to show the correlation between complexity and fan-out. Using different colours for the diagrams allows you and your team to quickly switch between the different representations.
Method level treemaps
Packages contain classes, but classes are not the smallest element in OO programmes; classes contain, among other elements, methods. An useful variation of a metrics treemap is to treat classes merely as the intermediate branches in the overall structure and focus on methods as the leaves. This results in treemaps that show the distribution of method level metrics across the codebase.
{jm: missing treemap}
The treemap above shows two areas of a codebase, one that has many small leaf rectangles representing short methods, indicating that this area of the codebase defines a set of DTOs with mostly one line getters and setters. The other area contains many large rectangles representing an area of the codebase that contains longer methods with complex controller logic.
Non-Code Metric Treemaps
Going beyond these examples, it is also possible to display non-metric information. For example the dominant committer of a file. In such a case, each committer would be mapped to an individual colour, and rectangles would be shaded in the colour of the dominant committer ,or in grey if no single committer accounted for more than a certain percentage of commits. Such a view would show whether a development team has bought into collective code ownership, or whether developers have carved off individual packages for themselves. That said, other visualisations, such as code ownership distribution maps (see xxx) can be more useful for such cases.
Fill-level
The treemaps discussed so far visualise two metrics through the size and colour of the rectangles. We have to accept that we cannot show a third metric through varying width and height independently because the aspect ratio is under control of the tiling algorithm. What we can vary, though, is the surface area of the rectangle that is coloured. For a maximum value of the metric the entire leaf rectangle is filled with colour, and for smaller values of the metric the filled area is gradually reduced and replaced by a neutral colour such as grey or white. This makes it possible to show a third metric in the treemap. However, if that third metric is low for many classes, then in these classes the colour becomes less visible, reducing usability of the map.
{jm: missing treemap}
Cushion treemaps
The visual variation that NDepend (for example) does, easier to size sizes.
{ed: not sure i have an opinion on them}
More
Treemaps for space-constrained visualization of hierarchies A good overview of the history and development of treemaps as well as a list of variations, such as Voronoi Treemaps.
Implementation Notes
Possible Tools: InfoVis Requirements: Snapshot of codebase
The implementation of this visualisation follows the typical three-step pattern, data acquisition, transformation, and visualisation. Metrics can be calculated with a variety of tools metioned earlier (see xxx) and the tool should be set up to write the metrics on a class level into a text-based format such as XML or CSV.
There are several tools available for drawing treemaps, and the transformation step obviously depends largely on the input format of the visualisation tool. For this implementation we’ll use a toolkit called InfoVis.
The InfoVis Toolkit is an open source toolkit to draw treemaps, either batched or in an interactive application. It is written in Java but of course it is suitable to render treemaps representing code written in any language. Development seems to have stalled and there are some issues with running it on Java 6, but InfoVis is still a good implementation with a very easy to generate input format and an intuitive user interface, which makes it a good choice for our purposes.
Data Aquisition
{jm: maybe put a step in here on how to get JRuby into TM3 format}
The input file format for InfoVis, named TM3, is very simple. The following excerpt shows data for the first few classes of the JRuby code base.
FLENGTH CDAC CFOC MCOUNT WMCloc WMCcc
INTEGER INTEGER INTEGER INTEGER INTEGER INTEGER
487 6 16 15 422 87 org jruby anno AnnotationBinder
21 0 1 0 0 0 org jruby anno Coercion
14 0 0 0 0 0 org jruby anno CoercionType
5 0 0 0 0 0 org jruby anno FrameField
69 6 9 1 54 11 org jruby anno InvokerGenerator
136 1 3 4 93 26 org jruby anno JavaMethodDescriptor
20 0 0 0 0 0 org jruby anno JRubyClass
The first line contains the labels of the values, the second line their data types. Both are tab separated. The remaining lines contain the values, one line per leaf in the underlying tree. Appended to the values in each line is path from the root to the leaf followed by the label for the leaf node, all of which is tab separated as well. Sometimes non-XML formats are refreshingly easy to work with.
Metrics are abbreviated where FLENGTH is the length of the file, and WMCcc stands for “Weighted Method Count (cyclomatic complexity)”, which is a count of the methods where each method is not simply counted as 1 but where it is weighted by its cyclomatic complexity. In other words, this is the sum of the cyclomatic complexity of all methods in a class.
Transformation and Visualization
The interactive Java application makes it possible to map various fields of the input file, likely representing different class-level metrics, onto different aspects of the treemap, size and colour being two obvious ones. It implements several different tiling algorithms, including Squarified. The screenshot below shows the settings used for the JRuby tree map above.
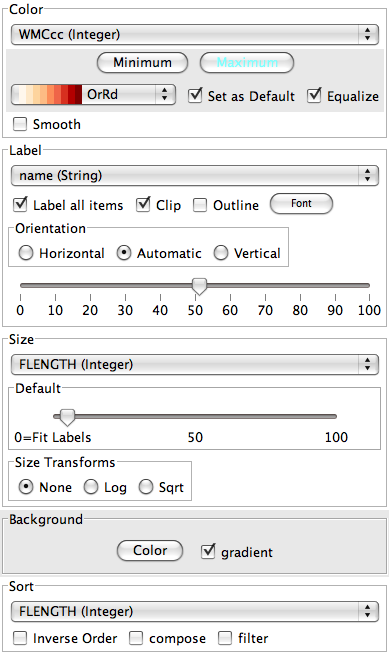
As mentioned above the Squarified tiling algorithm does not normally maintain an ordering of the rectangles at the leaf level. InfoVis, however, can sort the rectangles with Squarified and experience shows that sorting the treemap by the same metric that is mapped to the size of the leaf rectangles results in better looking treemaps.