Test-to-Code ratio chart
Are we writing enough tests? Are the tests good? Are we getting better?
On your team developers are writing unit tests. They care about test coverage and maybe even run a report on it as part of the continuous integration build. They also refactor code, and sometimes they wonder whether, as it is often claimed, the unit tests provide a safety net that ensures that the refactoring does not introduce regressions, or whether a lot of unit tests need to be changed following each refactoring, holding up the pace of development. Maybe it is possible to write too many tests.
The test-to-code ratio chart provides an overview of the ratio between lines of test code and lines of production code over an extended period of time. Assuming that test coverage is relatively constant, because the team practices test-driven development or actively measures coverage, any change in the ratio is interesting. It can indicate that the team has become more effective writing unit tests or it can show that comparatively more tests need to be written.
What you’ll see
The ratio chart is a simple line chart, with time on the x-axis and the ratio on the y-axis. The ratio is expressed as number of lines of test code per line of production code. A value greater than 1 indicates that there is more test code than production code in the system. For each day the data of all classes in the system is aggregated into a single value. Unlike other visualisations we are not interested in a static analysis of the codebase at a point in time, but purely the development of one very highly aggregated metric over time.
If possible the chart also contains markers on the time axis indicating important events in the project. These can be release dates, the end of iterations, or changes in the team structure. Having these events visible in the chart makes it easier to correlate changes in the test-to-code ratio to external events; and experience shows that most changes are related to external events.
Example: Development project
{ed: I’ll try to get clearance from the client. We might be allowed to mention their name.}
Test-to-Code ratio for the first 15 months of a project
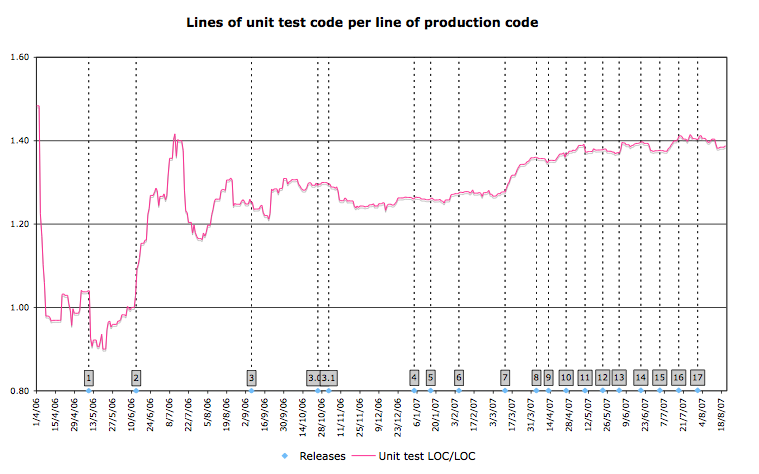
The chart shown above covers the first 15.5 months of a development project that set out to build a public facing website using a standard Java Open Source stack. The project started from a blank sheet with no code, and all developers, as well as management, were keen to use test-driven development, ie. writing unit tests just before or along with production code. In addition, the team used a variety of acceptance, integration, and performance tests; these are not reflected in the chart, though.
Releases are marked with dotted lines and a label showing the release number. Initially the team had weekly iterations and the dates of releases up to release 4 were driven by external factors and scope. After that the team moved towards a more steady release rhythm, and starting with release 10 switched to two-week iterations with a release at the end of each iteration.
The different releases show fairly different test-to-code ratios and trends. In the following paragraphs we relate the ratio to project events.
Development of release 1 was carried out by a very small team of senior developers experienced in test-driven development. The goal of the release was to prove the viability of the chosen technology stack. In the first week the test-to-code ratio is over 1.4:1, which is a high value for Java, but given the tiny size of the codebase the value can, and does, change rapidly. Throughout the rest of the time leading up to release 1 the ratio oscillates around 1:1. Given the still very modest size of the codebase larger movements in the ratio are more likely to occur.
Release 2 focussed on fleshing out the application architecture and was developed by the same, experienced, team that was responsible for release 1. After an initial drop in the test-to-code ratio, the team gradually reaches a 1:1 ratio around the release date. As the size of the codebase is getting bigger, larger swings become less likely.
After release 2 the overall project team was satisfied with the technology stack and application architecture, and development started in earnest for the first public launch. This brought dramatic changes to the development team. Its size more than doubled and the original developers were complemented by developers experienced in the domain but unfamiliar with Java and TDD as well as more junior developers who were familiar with Java and TDD.
Following the changes in team structure in the course of about one month the ratio shoots up from 1:1 to over 1.4:1. The change is immediate. A first indication that something had changed came when the senior developers realised that often times code was written from scratch, rather than refactoring existing classes to make them more generic so that they could handle the original use case and the new requirements. Apparently it was easier to write something from scratch than to refactor existing code and fix the tests failing as a consequence of the changes.
Analysis revealed that the newer team members, who had less experience with TDD, had started to write too much test code. It is a good sign that, missing some experience to judge what the right amount of testing is, the team erred on the side of writing too much test code. However, as with many other things, too much of something good can also have negative consequences. In the case of test code it makes it harder to refactor existing code because a single change affects more than just a couple of tests.
Further analysis showed that unit tests had been written by cloning (read: copy-pasting) previous test cases, leaving most of the setup and many assertions in the new tests, just adding variation in between. These repeated setups and assertions meant that the same behaviour was tested multiple times, thus hindering refactoring. They were also responsible for the visible growth in the test-to-code ratio.
Once the team realised the problem it took active measures to improve the test code. The chart not only shows the story of the problem, but after the peak around the middle of June it allowed the team to get feedback on the impact of their changes. We can see the ratio drop substantially in the following weeks, probably due to some concerted effort to clean up many existing tests. In the run-up to the release the ratio does climb up again, before it drops again steeply around the middle of July. At this point the codebase is big enough that changes of the ratio on this scale reflect significant change and effort.
Release 3 marked the point of feature completeness and the basis for the public launch. For the first weeks after release 3 the test-to-code ratio is further reduced before shooting up again around the end of September. At this point many bug reports from automated and manual user acceptance testing had flown to the team, prompting them to write unit tests to cover known bugs, but no new functionality. For the remainder of time leading up to release 3.1, which was the public launch, the ratio remains relatively constant around 1.3:1.
Following only the first three releases shows how much the simple line graph reveals about the team and their behaviour and how it is useful not only to detect potential problems but also to track the success of improvements.
{ed: should I cut the chart to stop after release 3.1? feels painful to throw away data, but explaining the whole chart feels too much.}
How it works
{ed: Hm…. Is this one where the story/example is sufficient?}
Implementation notes
only two steps… aggregation together with acquisition… only shell tools / miniamal scripts… doesn’t work on standard Windows command line… this is not what was used to create the example graph; that was done with a tool that collected more metrics and vis in Excel
Calculating lines of code
Calculating lines of code is a bit of a science in itself. It is not clear what to count; only the lines of code inside method bodies, all non-blank non-comment lines, or all lines in source code files? For the purpose of this visualisation, because it is highly aggregated and based on a ratio, it is sufficient to simply count the lines of all source code files, which can be achieved with simple text-based tools such as the wc shell command.
Many Java projects have a directory structure that stores test and production code in different directories, usually src/main/java for production code and src/main/test for test code. With such a project lines can be counted as follows:
find src/main/java -name '*.java' | xargs wc -l | tail -1 find src/main/test -name '*.java' | xargs wc -l | tail -1
The find command finds all source files based on the file extension. The names of the files are passed to the wc command, which counts the lines in the files. It prints the line count for each file and a summary line with the total number at the end. As we are only interested in the summary we are filtering all lines but the last from the output with the tail command. The xargs command is necessary to change the output of the find command into an argument list for the wc command.
Iterating over revisions
Provided the code is stored in a source control management system and the system has an efficient mechanism to retrieve versions by date, it is possible to create the chart at any point in time. If, for example, the source code is stored in Subversion, it can be checked out with a command like this. The timestamp corresponds to the date at which we want to start the analysis.
svn co https://src.springframework.org/svn/spring-framework/trunk/ -r {2008-07-12}
With the source code available the commands described above can be used to calculate the lines of code at that point in time. To iterate over the changes, on a daily or weekly basis, in case of Subversion the update command can be used. By updating, instead of checking out a new copy, only the changes in the time interval need to be transmitted, which greatly speeds up the process. The command is a follows:
svn up https://src.springframework.org/svn/spring-framework/trunk/ -r {2008-07-19} trunk
What is missing for the data aggregation step is a script that automates these tasks and prints lines with the timestamp and the production and test code counts, e.g. 2008-07-19 5866 3434. The Ruby script included below is an example for such a script.
1 require 'date'
2
3 def run(date, endDate)
4 while date <= endDate
5 `svn up -r {#{date.to_s}} trunk`
6 prod = getloc("trunk/*/src/main")
7 test = getloc("trunk/*/src/test")
8 puts "#{date} #{prod} #{test}"
9 date += 7
10 end
11 end
12
13 def getloc(directory)
14 `find #{directory} -name '*.java' | xargs wc -l | tail -1`.to_i
15 end
16
17 run(Date.new(2008, 7, 12), Date.new(2011, 8, 4))
The run method between lines 3 and 11 contains the main loop, iterating until it reaches the predetermined end date. For each date it first updates the source to that point in time, then uses the getloc method described below to calculate the lines of production and test code, which it prints alongside the date. In line 9 it increments the date by 7 days. The time span for this visualisation is so large that it is more reasonable to calculate the ratio once per week, and not once per day.
The lines of code calculation using shell commands is used in the getloc method in line 14. Luckily the “to integer” functionality in Ruby is quite forgiving and can directly convert the output of the commands into a single number. If you are unfamiliar with Ruby or the backtick notation, shell commands inside backticks are evaluated and the value of the expression is the output of the shell command.
Depending on the size of the codebase, the amount of changes, and the network connectivity to the source code repository such a script can take several hours to run. It is therefore useful to store the output in a text file, rather than sending it directly to the graphing stage:
ruby tcratio.rb > tcratio.data
Running the script like this assumes that it is stored in the same directory into which the code was checked out, i.e. it should be next to the trunk directory.
Drawing the chart
The chart from the example was created with Excel but we would like to show a fully scripted approach using Gnuplot. The result will look like this.
{ed: need to better example, improved fonts, and direct output}
Starting from the tcratio.data script the chart can be generated with the following Gnuplot script:
1 set title "Test code to production code ratio"
2
3 set xdata time
4 set timefmt "%Y-%m-%d"
5
6 set format x "%b %Y"
7 set format y "%.2f"
8
9 set yrange [0:]
10
11 set grid ytics
12 set grid xtics
13 set xtics nomirror
14 set ytics nomirror
15
16 plot "tcratio.data" using 1:($3/$2) with lines linecolor 3 linewidth 2 notitle
Variations
Test-ratio in Ruby
Often much higher, more expressive language for code but tests are structurally similar?
{ed: can we get an example? is this really a variation? where else to put it otherwise?}
Branching point density
Ratio of loc to cyclo. More pressure = more procedural code = higher branching point density, more time to write good code = more use of oo = more polymorphism = lower branching point density